
Author: Zhiyuan Jiang NUDT Xiyue Jiang NUDT Ahmad Hazimeh
Code: https://github.com/HexHive/Igor
Introducetion: 覆盖减少模糊器+CFG相似性度量,对crash进行聚类
Topic: Crash Bucket, Root Cause
Where: CCS 2021
Year: 2021
本文只是学习并记录笔记,如有错误或不足请谅解指正,谢谢!
摘要
- 解决的问题:当前工具对crash进行分类效果不好
- 已有的方案:通过动态分析程序行为,来定位root cause(POMP AURORA REPT等);基于崩溃位置crash sites 、覆盖信息 coverages profiles 或调用栈 stack hashes来进行crash分类
- 本文提出的创新方案概述:最小化测试用例,根据它们的CFG图,通过Weisfeiler-Lehman Subtree Kernel algorithm聚类算法为crash进行分类
- 实验效果:对10个程序产生的254,000个poc,产生的39个bug分成了48聚类。而当前其他方法会大一个数量级
Crash bucketing 问题
崩溃分类的目的:给定大量的崩溃测试用例,哪些崩溃会触发相同的错误?
当前方案:
- 基于Crash Site:完全不准确
- 基于Coverages Profiles:覆盖引导的Fuzz(如AFL)
- 如AFL崩溃去重原则:
①若该崩溃的路径出现了之前没执行过的路径,则认为是新的崩溃
②若该崩溃的路径不包括之前崩溃总是执行了的路径,则认为是新的崩溃 - 缺点:对bug路径的轻微修改就被认为一个新的crash,对控制流细微变化很敏感,高估了2-3个数量级。
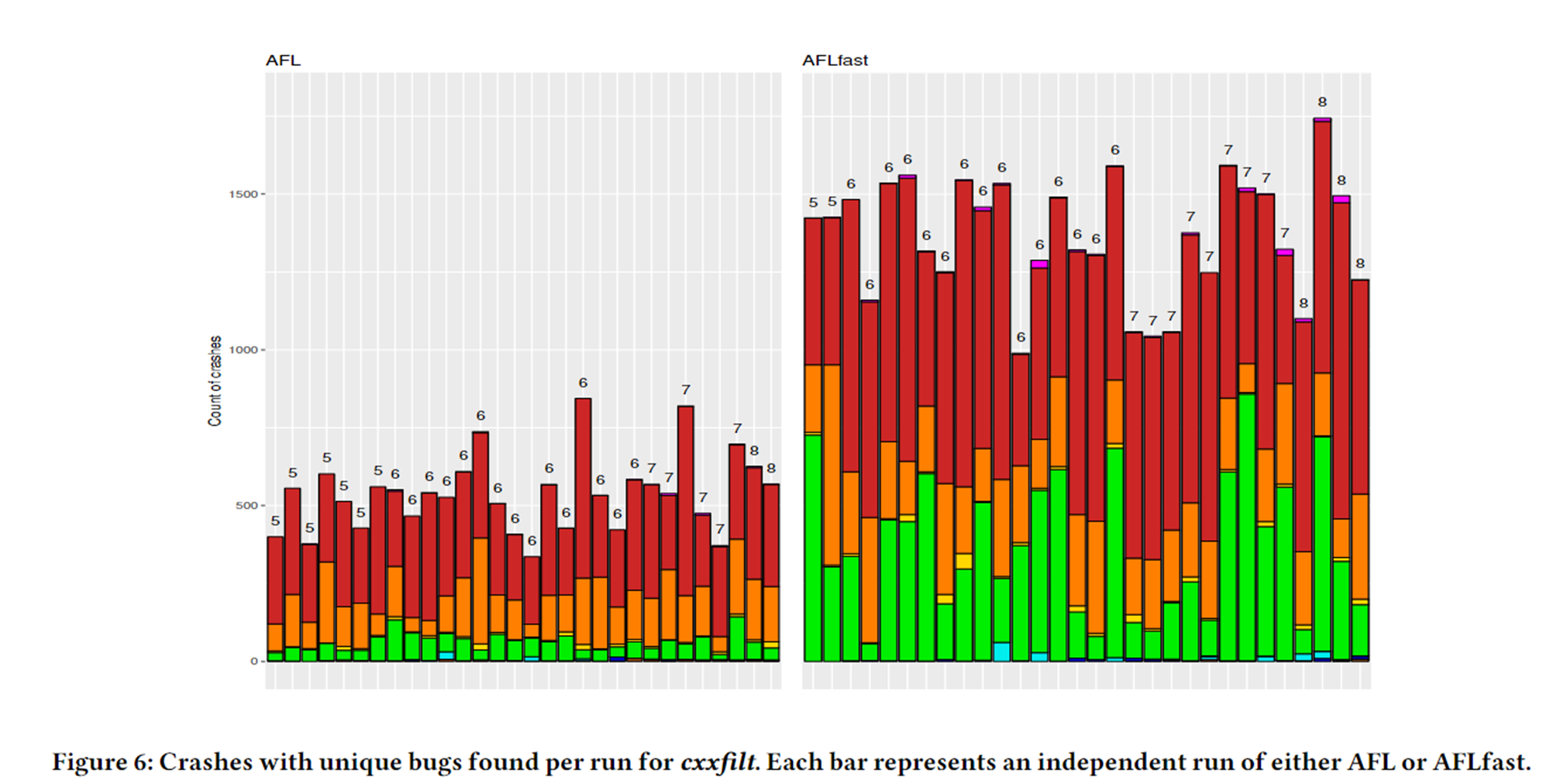
- 如AFL崩溃去重原则:
- 基于Stack Hashes: function-sensitive,被用于honggfuzz和clusterfuzz
- 优点: ①易于部署
②有论文研究:超过80%的崩溃根因是在崩溃调用栈上的 - 缺点:
- 可能超过正确数量:输入至崩溃之间的路径不同
- 可能少于正确数量:不同错误共享相同的调用序列
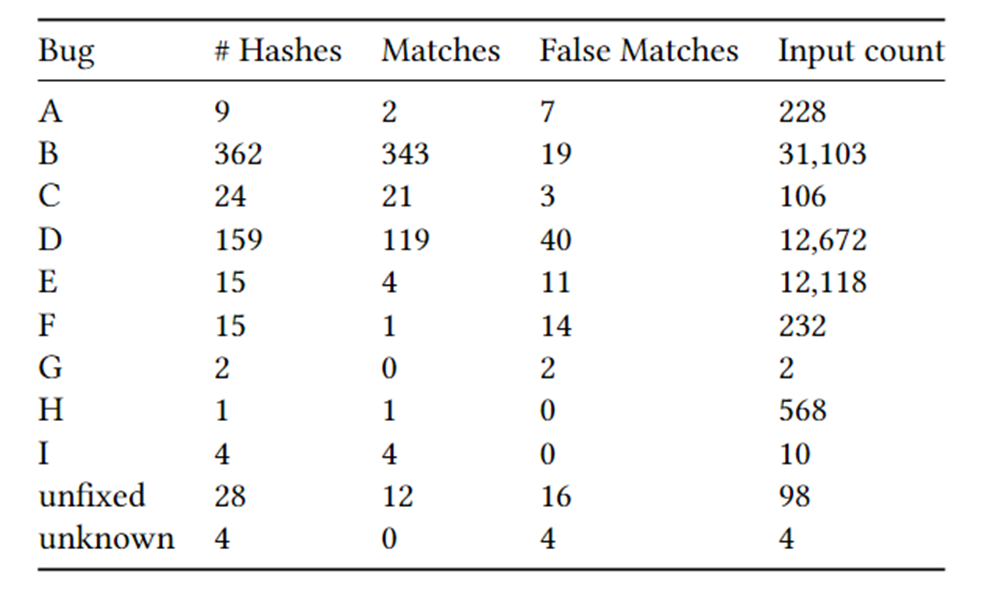
- 优点: ①易于部署
- 基于Root Cause:根据root cause来分类(POMP AURORA REPT等)
- 优点:比Stack Hashes更精确
- 缺点:内存、时间消耗较大
根据当前主要流行的方案的优缺点,可以看到:基于Stack Hashes和基于Coverages Profiles的方法是当前主要被实用的崩溃分类/去重方法,但他们不准确的一个主要原因就是:对程序的执行行为路径的变化非常敏感。而当前主流的模糊测试工具都是以覆盖率为导向的(Coverage-guided),其目标就是最大化代码覆盖率,这加剧了这一问题。
因此,作者认为,覆盖率最大化确实会有益于模糊测试,但不利于崩溃分类,那么就反其道而行之,将覆盖率最小化,易于崩溃分类。
框架
覆盖率最大化策略。是fuzz过程中发现crash的有效手段;而覆盖率最小化fuzz,是最小化执行跟踪并实现有效的崩溃分组的关键。
因此作者修剪不必要的执行跟踪元素,使crash的标签更精确,实现重复数据的消除。还通过使用CFG来更完整地查看crash的执行轨迹,来解决调用栈的缺点。
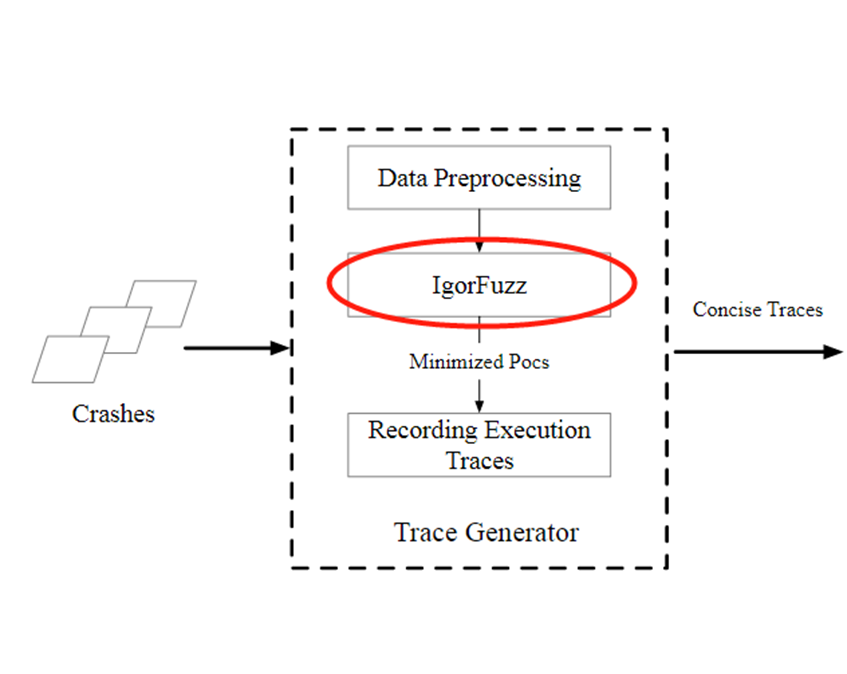
1、实现了覆盖减少模糊器(Igorfuzz),获取最小化的测试用例
2、对最小化执行跟踪的CFG图进行相似性比较,对其进行分组、聚类(使用Weisfeiler-Lehman Subtree Kernel algorithm)
3、评估分类的真实性基准
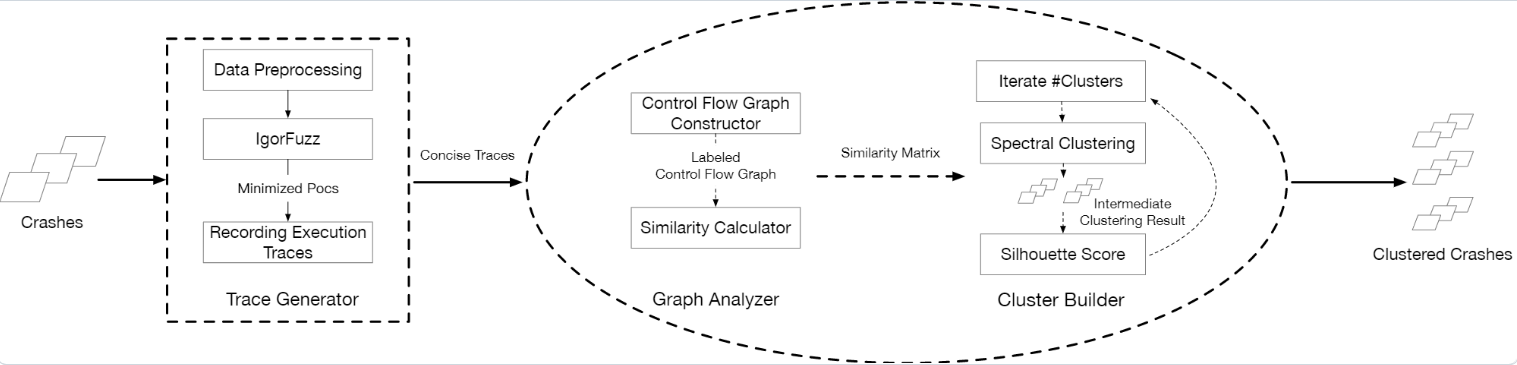
具体方法
作者认为,相同root-cause的bug,它们的execution trace中有相同的核心行为。基于上述认识,作者认为可以选取合适粒度的核心行为来进行crash聚类。
1、Data Preprocessing
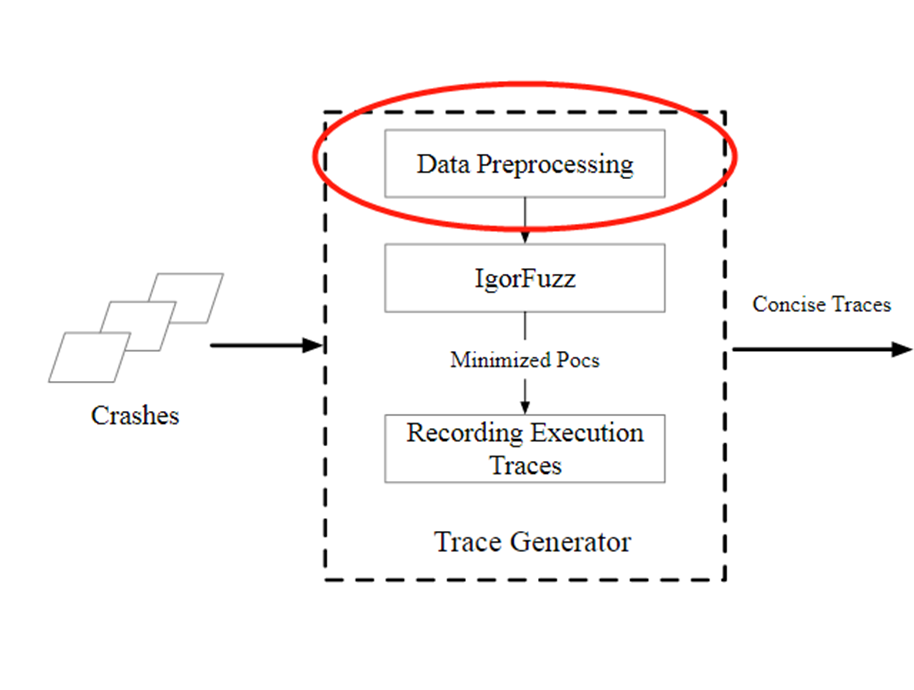
取样
首先通过使用Stack Hashes对全部崩溃进行第一次分类
注意,前面提到Stack Hashes不准确,于是作者采用last N = full length的方式进行崩溃栈分类,这虽然会分出很多种类,但能够大幅度确保一个崩溃栈映射到唯一一种漏洞上的概率。即,作者认为:一个漏洞可能有多个崩溃栈,而一个崩溃栈一般只映射到唯一一个漏洞上。(作者的测试数据:三个程序的71个bug中,有6个存在共享Stack hashes)
每种Stack hash取最多50个POC
这样的好处是可以对高相似度的POC进行去重,不影响精度的同时减低处理成本。
最小化
通过afl-tmin进行POC最小化(唯一优化的度量:缩小文件长度),可以间接缩短执行路径
- 减小输入的大小能更快的进行处理,产生更高的模糊测试吞吐量
- 通过从输入中删除多余的字节,模糊器的突变更有可能修改对程序行为至关重要的字节
- 潜在风险:可能会引入新的bug,但几乎可以忽略不计(1/5531)
2、Coverage-minimizing fuzzing
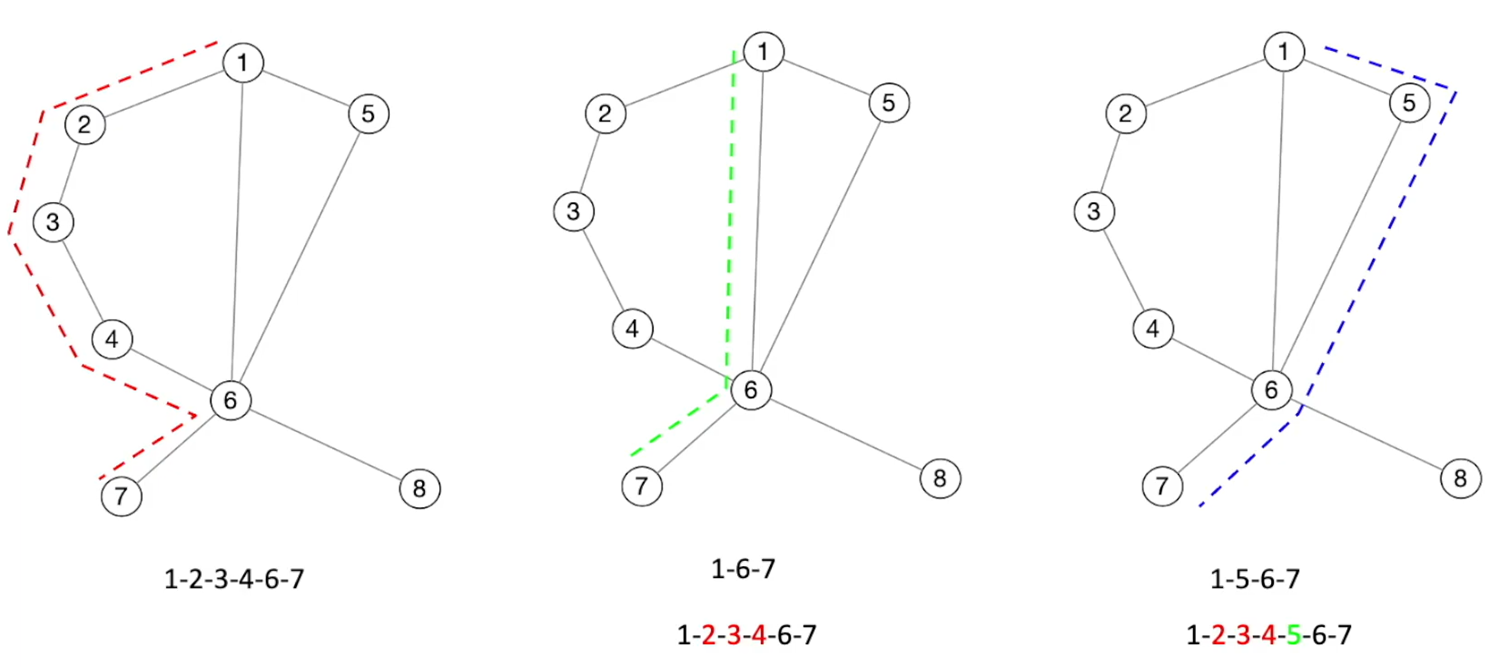
①只有错误的那部分代码被执行,才会触发crash
②减少输入文件的长度,并不意味着减少对应的执行路径的长度
目标:寻找shortest bug-triggering path
通过修改AFL++的崩溃探索模式,形成了Igorfuzz
修改的规则:
- 修改isInteresting方法,只保留崩溃测试用例
- 种子不执行公共边(即,尽管总体覆盖率可能会增加,但至少一个边缘不再执行)
- 种子执行一些命中次数较少的边(至少一条边执行次数更少,而没有某一条边会执行更多次数)
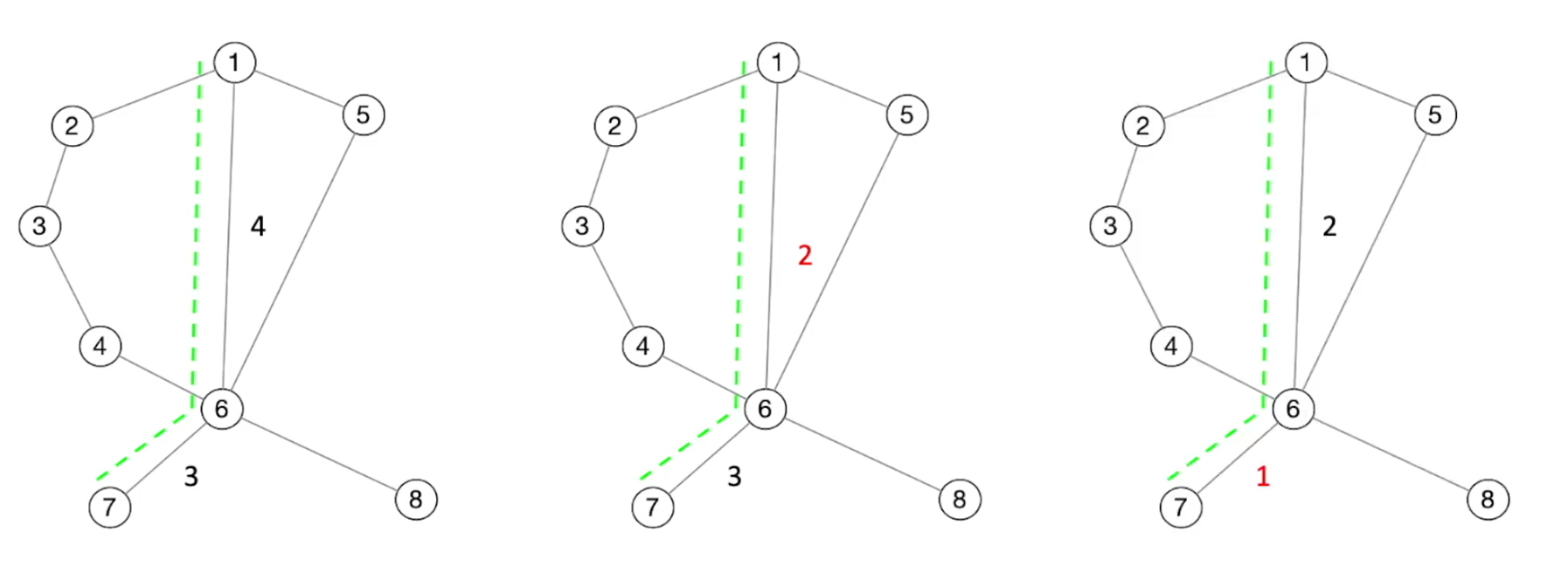
同时,对于“局部最小化”的问题(个人理解就是:fuzz在这个局部进行优化,一直认为当前路径已经是最小路径了,但实际上可能发生在较远的路径上)也能很好的处理
能量调度:分配给路径更短的种子
Fuzz输出选择标准:
① BitmapSize – 显示触发了多少唯一边
② Crash Sites – 辅助功能:避免产出新类型的崩溃
最后,使用Intel PIN进行动态追踪,获取控制流
去除的噪声:
一、外部调用(如libc)
二、崩溃发生后的函数调用(如ASAN)
3、PoC similarity and bug clustering
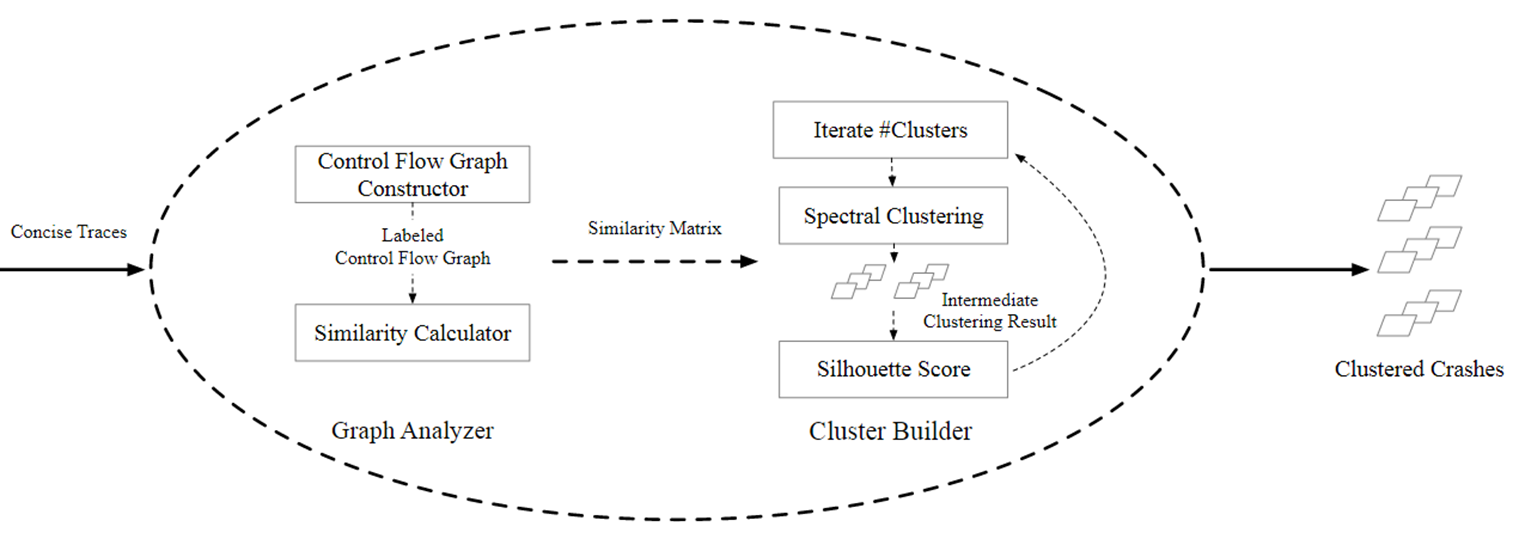
① 使用NetworkX将trace生成DCFG,使用GraKeL将DCFG转为相似矩阵
② 使用Weisfeiler-Lehman Subtree Kernel algorithm聚类算法
默认运行15次聚类,从2到16列举聚类的数量,每次计算轮廓分数(silhouette score),输出分数最高的聚类结果
实验结果
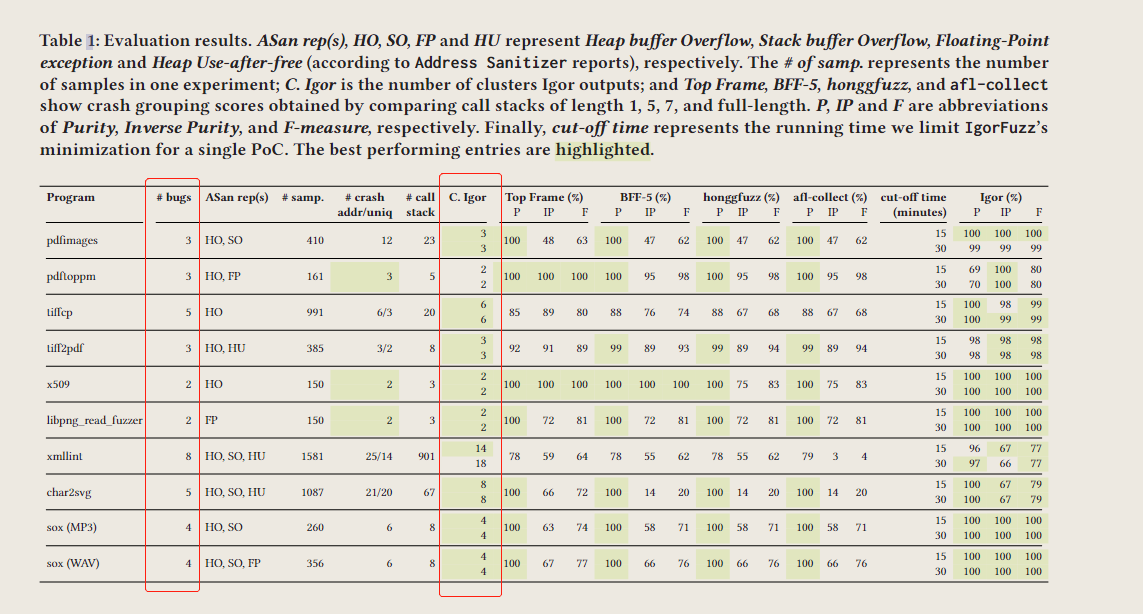
其中,后面比较的Top Frame(N=1)、BFF-5(N=5)、honggfuzz(N=7)、afl-collect(N=FULL)都是采用基于堆栈哈希来进行分类的,只是深度不同
最小化实验效果:
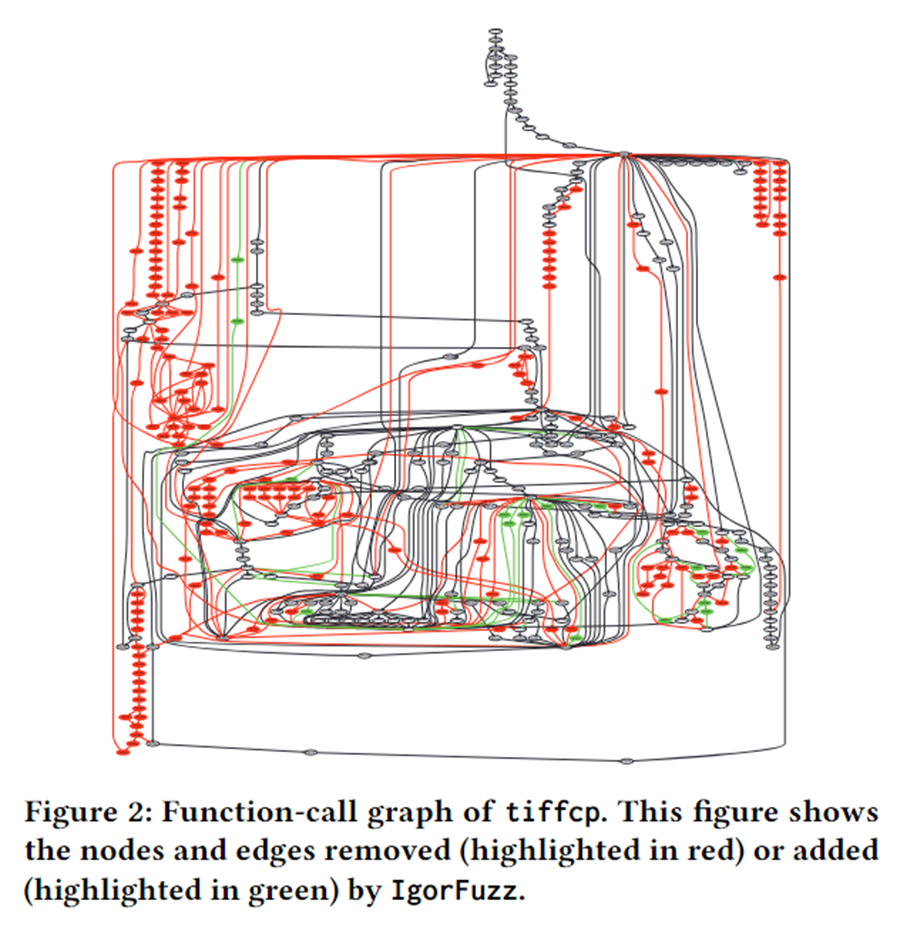
如果不进行最小化,直接用原版crash进行聚类,效果不佳:
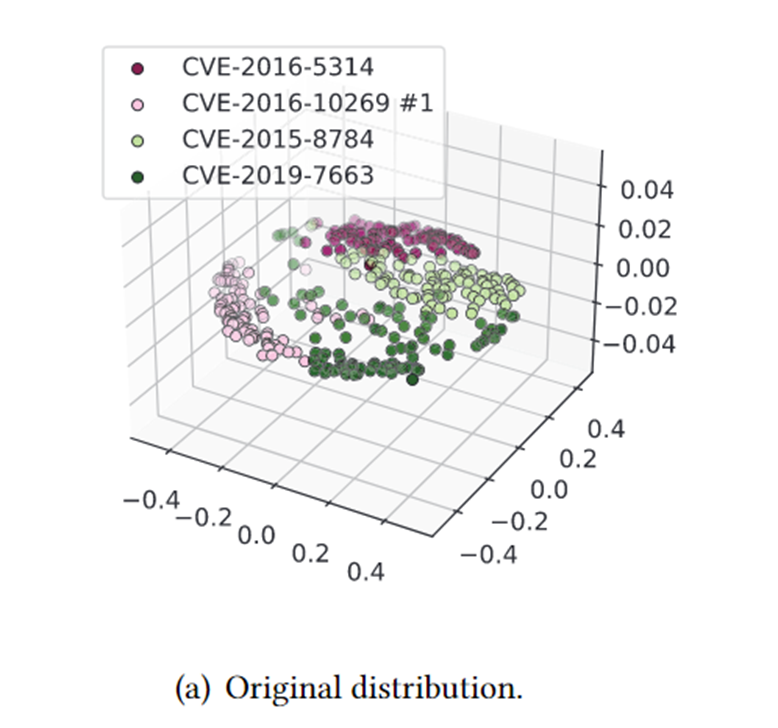
最小化后的聚类,效果较好:
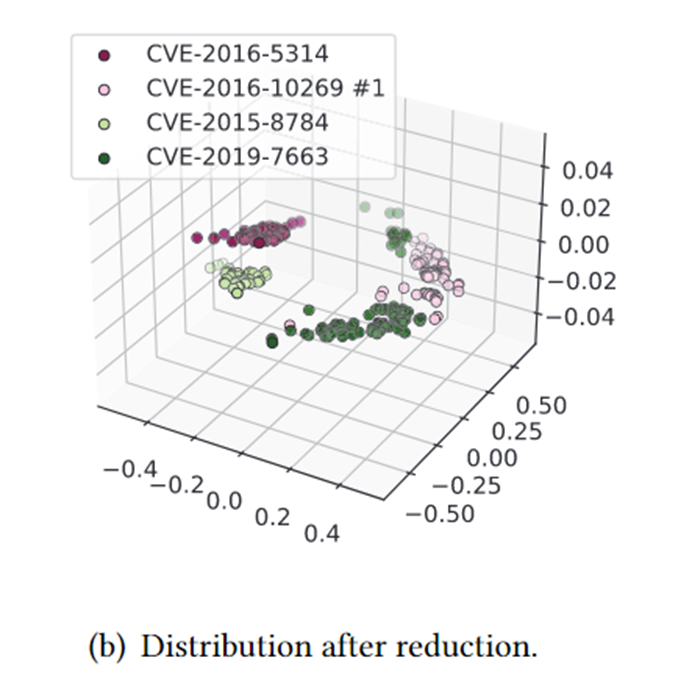
局限性
Igor局限性:
① 使用轮廓分数(silhouette score)不能保证区分所有的聚类,需要手动检查。如果同一聚类内的样本之间仍然存在差距,则表明需要进行第二次聚类。
② 当输入实际上只有一种bug时,聚类仍然会对其进行分类(2至16)。当Igor发现自己给出的组号大于afl-collect时,它将调用afl-collect对崩溃进行分组。