
Author: Tim Blazytko, Moritz Schlögel, Cornelius Aschermann, Ali Abbasi, Joel Frank, Simon Wörner, and Thorsten Holz, Ruhr-Universität Bochum
Code: https://github.com/RUB-SysSec/aurora
Topic: Root Cause
URL: https://www.usenix.org/conference/usenixsecurity20/presentation/blazytko
Where: 29th USENIX Security Symposium
Year: 2020
Introducetion: 根因分析:一种采用Fuzz+动态执行+数理统计的方法
本文只是学习并记录笔记,如有错误或不足请谅解指正,谢谢!
摘要
- 已有的解决方案及不足:各种依赖于反向执行和反向污点分析等技术的方法(如POMP 2017)。不足:这些技术可能只限于某些crash类型,或者只为分析人员提供汇编指令,但没有提供有关故障的更多说明
- 解决的问题:不仅能识别二进制程序崩溃的根本原因,还可以为分析人员提供了该位置产生崩溃的解释;相对于以往的工作,能够识别对于不存在数据依赖关系的错误(如类型混淆错误)
- 本文提出的创新方案概述:
- 从导致崩溃的输出开始,生产一组不同的相似输入(部分会导致崩溃、另一部分正常运行)
- 执行输入时,跟踪程序状态,生成
predicates(例如:产生崩溃与不产生崩溃输入之间的行为差异的简单布尔表达式) - 通过
predicates,揭示根本原因的位置,并提供了该位置产生崩溃的解释
- 实验效果 在25个软件漏洞上评估,表明:再复杂的bug,AURORA也能发现根本原因(修复与崩溃之间有数百万条指令),并且能够处理root cause和crash之间不存在数据依赖的错误,例如类型混淆错误。
问题
找到新的崩溃输入已较为容易和自动化,而对崩溃分类、处理还需要人工完成
- 修复时间成本大:FUZZ—无数崩溃—负责修复—不堪重负
- crash分类不准确:通常采用某一种度量进行分类(覆盖率或者调用栈的hash),一般每一类有一个crash就够了。但该分类方法容易不准确,且可能产生太多的类
- 如何定位崩溃原因?(通常崩溃的根本原因比崩溃位置更早)(当前方法:ASAN+手动回溯分析)
AURORA框架
- 选择一个crash input文件,并产生一组相似的输入(一些会导致崩溃,另一些不会)
- 对于每个新的输入,执行、跟踪程序内部状态(每条指令的控制流信息、寄存器值),以此创建一组
predicates(布尔表达式) - 根据predicates,计算此输入是否会导致崩溃(怎么计算?) predicates :会获取感兴趣的行为,如:是否执行了某一特定分支、寄存器是否包含可疑的小数
具体方法
举例
作者举例 Ruby code mruby解释器 类型混淆错误(type confusion bug):
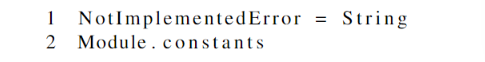
- 异常类型
NotImplementedError被修改为字符串类型的别名。因此,将来创建的每个NotImplementedError实例都将是一个字符串,而不是预期的异常。 - 调用Module.constants函数,但函数不存在,触发
NotImplementedError,实际上生成一个字符串对象 - 传递给mruby的自定义异常处理函数,函数假定对象具有异常属性,因此不检查,并添加”Module.constants not implemented”至该字符串对象上
- 最终在取消指针引用的时候,将长度字段解释为地址,非法内存访问,程序崩溃
修复:在异常处理函数中添加类型检查
根因分析通常采用的方法
- 人工调试:时间成本长,复杂
- sanitizer:ASAN、MSAN等,但不能识别上述类型混淆错误
- 反向污点分析:近期对这一方向的研究比较多,如:REPT(2018 usenix)、RETracer(2016 IEEE)、POMP(2017 usenix),DEEPVSA(2019 usenix)但同样对于上述类型混淆错误不起作用(崩溃点与根本原因地址之间没有直接的数据流)
- crash勘察:AFL crash exploration mode 将崩溃的输入作为种子,变异生成新的输入,保留仍导致崩溃的输入。这些输入会有新的路径覆盖。
fuzz过程的一个问题:
对于作者给出的例子,为了对crash的根本原因有新的见解,需要崩溃探索模式来触发与类型混淆相关的新行为,即:Fuzzer需要向NotImplementedError分配除了String的另一种类型,而AFL的突变模式大概率会变成如“Stringgg”或“STRR”之类的内容。 |
AURORA设计
核心思想:定位崩溃和非崩溃输入之间的行为差异。首先创建与崩溃相关的程序行为数据集,然后监控相关的输入行为,最后对它们进行比较分析。这是基于这样一种观点,即崩溃的输入在某种程度上必须从语义上偏离非崩溃的输入。直观地说,程序执行过程中导致偏差的第一个相关行为是根本原因。
步骤
- 首先创建两组输入:导致崩溃的输入、不导致崩溃的输入(理想情况:导致崩溃的输入都是同一个根本原因) 方法:将崩溃输入作为种子进行崩溃探索fuzzing(AFL crash exploration mode)https://lcamtuf.blogspot.com/2014/11/afl-fuzz-crash-exploration-mode.html
- 跟踪每一个输入的执行,将差异与结果联系起来,使用
predicates来形式化这一过程,具体跟踪的数据如下:- 对于执行的每条指令,我们记录所有修改的寄存器(包括通用寄存器和标志寄存器)的最小值和最大值(原因:限制循环导致的数据量。为什么合理?作者认为,导致崩溃的值通常以最小值或最大值的形式出现)
- 记录了每次内存写入的最大和最小存储值
- 没有收集有关目标地址的信息,由于:“we did not observe any benefit in tracing the memory addresses used”
- 保存粗略的控制流图
- 收集栈和堆的地址范围来测试某些指针是否使有效的堆栈指针
- 不跟踪共享库(减小开支)
- 消除对那些-从经验上来说-对在一个给定的二进制程序中发现错误不感兴趣的代码的追踪
- 结果:向分析人员提供崩溃相关解释和地址的列表,按它们(predicates )的预测质量和执行时间排序
Predicates
- 目的:以predicates(谓词)的形式区分崩溃与非崩溃运行之间的差异行为
- 组成(一个三元组)
- 语义描述(如布尔表达式)e. g., “the maximum value of rax at this position is less than 2” O(n ∗ log(n)) around 1,000 per instruction
- 被求值的指令地址
- 表示区分崩溃和非崩溃的能力的分数
换句话说,当谓词的计算结果为真时,分数表示认为会导致崩溃的概率。
得分较高的谓词标识了在根本原因和崩溃位置之间的路径上的某个代码位置。
最后,先按分数对这些谓词进行排序,然后按它们的执行顺序进行排序。给出这个排序后的谓词列表,人工分析人员就可以手动分析该错误。
- 具体形成predicates的步骤:
- 通过跟踪输入的行为获得结果:
- 收集所有输入的控制流程图转换
- 之后,计算指令集(由地址标识),这些指令与基于谓词的分析相关
- 为每条指令生成许多谓词,保存分数最高的谓词
- 通过跟踪输入的行为获得结果:
Predicates Type
- Control-flow Predicates
- has_edge_to:给定一条从 x 至 y 的控制流边,至少有一条从 x 到 y 的转换
- always_taken_to:从 x 出发的每个传出边都已被带到 y
- Register and Memory Predicates 对于每条指令,根据:写入寄存器或内存的所有值中的最小值和最大值,生成表达式,来生成谓词 表达式示例:
r = max(Rax) < c(如何构造?下面介绍)- is_heap_ptr(R)
- is_stack_ptr(R)
- Flag Predicates 检查carry, zero and overflow flag
Predicates Evaluation
每条指令,生成并测试所有类型的谓词,并存储得分最高的谓词。
谓词的质量:
谓词的质量,即,它对目标应用程序实际行为的预测程度 |
谓词三元组
- 语义描述(如布尔表达式:r = max(rax) < 2) |
对于每个谓词,有两个核心点:
①布尔表达式的判定数?②分数怎么计算?
判定数c的形成:(时间复杂度:O(n ∗ log(n)))
假如现存在以下四个输入文件,两个crash,两个non-crash;假设其中在某一条指令上,max(rax)的值如下
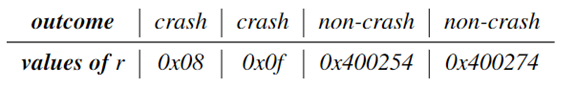
- 对于所有输入文件中,同一条指令中,该寄存器的值进行排序
- 首先设判定数等于第一个value,即:
c = 0x08,此时,对于布尔表达式r = max(rax) < c,四个都是false 其中,Cf = 2 , Ct = 0 , Nf = 0 , Nt = 2,带入作者的公式: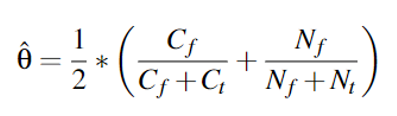 即:
即: 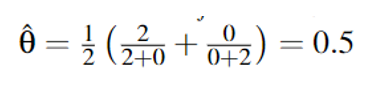
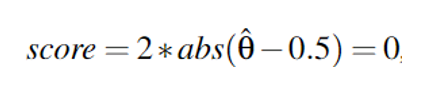 score = 0,表明这个c不是理想的值
score = 0,表明这个c不是理想的值 - 将判定数设为第二个value,重复步骤2,以此类推,发现当判定数c值为0x400254时,score = 1 ,最理想
分数计算:
- 设某一条指令中,一个谓词的语义描述为:
r = min(Rax) < c ,c = 0xff - 一共有1013个崩溃输入,2412个非崩溃输入 统计得到: Crash input : False = 1013, True = 0 Non-crash input : False = 2000, True = 412
- 使用公式
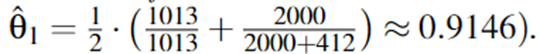 此时,谓词的分数为:
此时,谓词的分数为: 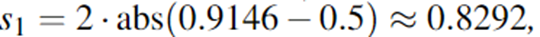
可以看到,判定数计算和分数计算的步骤几乎一致,也就是说,计算判定数的同时,就把分数也计算出来了。
同时作者还提到,绝大多数谓词与root cause无关,因此只保留分数大于0.9的谓词。
最后还对每个合适的谓词设置条件断点,并记录执行顺序。
回到前面作者提及的Ruby code mruby解释器 类型混淆错误 的例子:
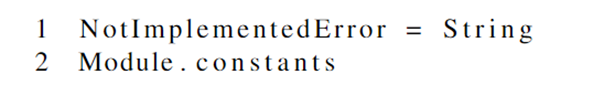
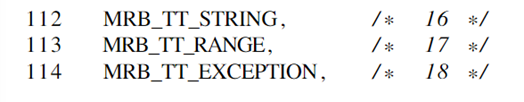
根据前面的步骤,可以分析得出,在触发崩溃的样本中,类型值被赋予了16(string类型),其应当是18,所以根本原因谓词的本身条件是:min(rax) < 17
Ranking
- 主要因素:谓词的分数 通过统计分析,每条指令获得一条最佳谓词,其分数表示谓词区分崩溃和非崩溃输入的程度。但大多数谓词是与崩溃无关的,因此作者筛选掉分数小于0.9的谓词,剩下的谓词确定了与错误有关的位置。 作者认为,程序执行前期的谓词更有可能对应于根本原因。
- 次要因素:谓词的执行顺序(解决分数并列问题) 为了知道每个谓词的执行顺序,作者为谓词设置了条件断点。执行输入时,计算每个断点在程序中的顺序。由于每个输入执行的路径不同,谓词的执行顺序不同,因此作者对每个谓词的断点进行平均求值。
开发与实验
- 输入数据集:作者对AFL(版本2.52b)进行了修改,将本来要丢弃的非崩溃输入保存到非崩溃输入集。
- 跟踪输入执行:作者为英特尔PIN[40](3.7版)实现了一个pintool,依靠英特尔的通用和特定架构的检测API,提取相关信息。
- 合成谓词解释:Rust 写的。合成、评估、排序所有谓词;条件断点使用ptrace syscall;使用addr2line获得谓词的函数名、行数。
实验
- 环境:Ubuntu 18.04 32核(基于Intel Xeon Silver 4114,2.20 GHz)和224 GiB RAM的云VM 禁用ASLR
- 对象:
- 10个堆缓冲区溢出
- 1个空指针引用
- 3个整数溢出
- 1个栈溢出
- 2个类型混淆(缺少类型检查)
- 3个未初始化变量
- 5个UAF
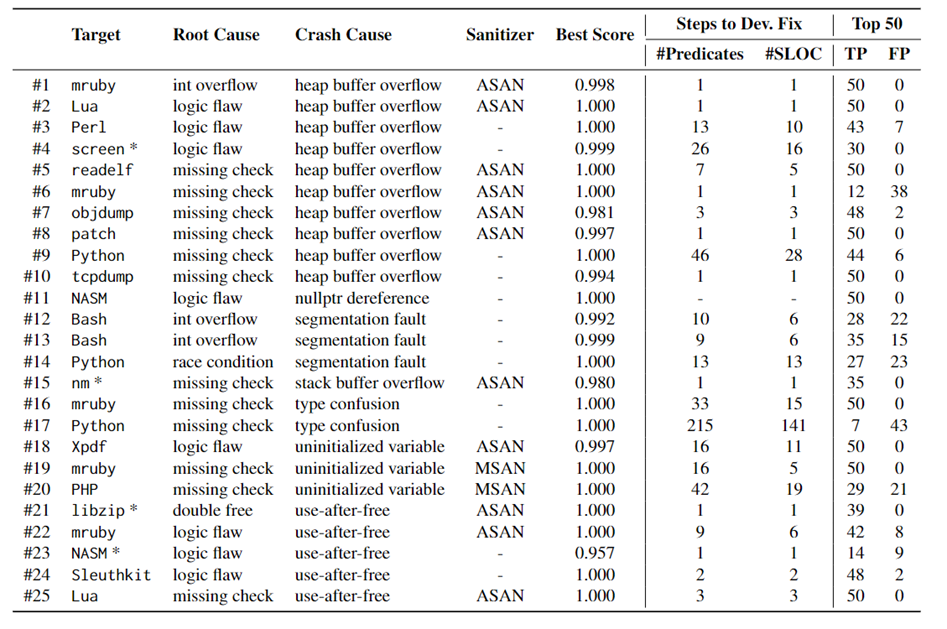
- Top 50 指提取出来的前50个谓词,与根因是否存在直接关联
- SLOC指需要检查的源代码行数量
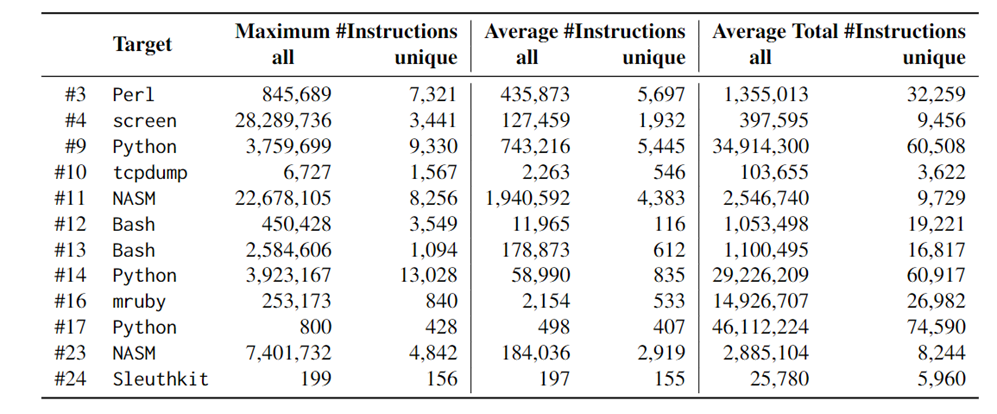
- 第一、二格:root cause 至崩溃点之间的指令数(最大、平均)
- 第三格:程序开始执行至崩溃点之间的指令数(平均)
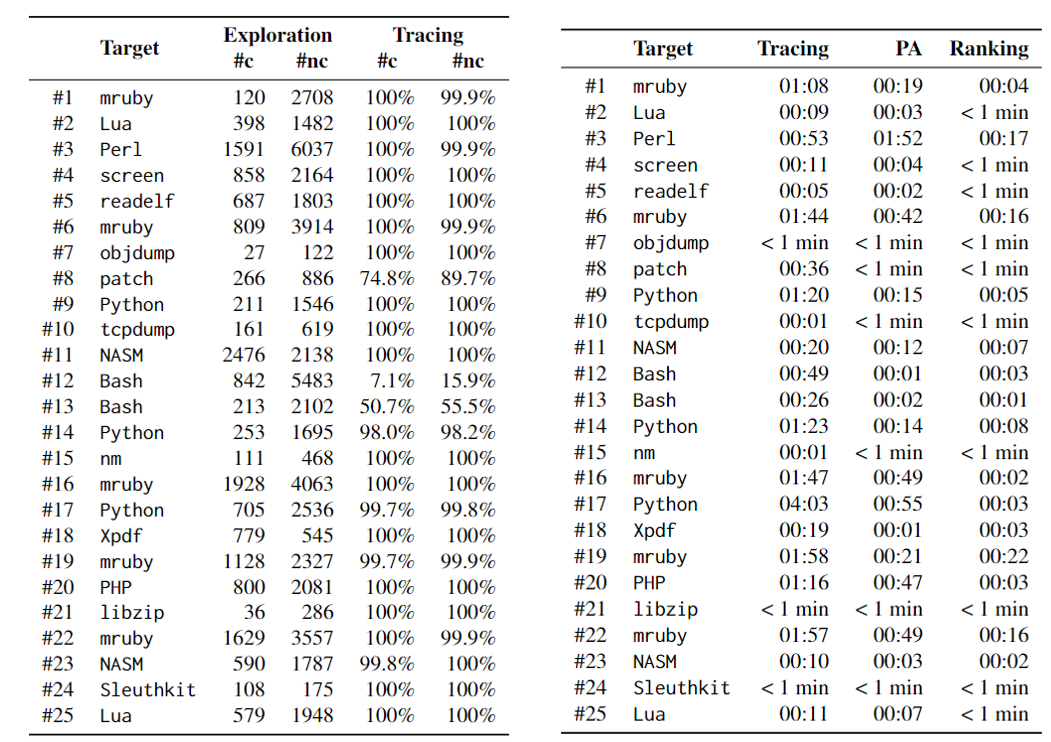
最后是时间成本分析
总结
- 解决了root cause 与崩溃点之间无数据流情况下的根因分析问题
- 核心思想:定位崩溃与非崩溃之间的行为差异(通过数理统计)
- 根因分析成功率及时间效率都较高(可以用更多实验来复现)