
Author: Hang Zhang and Zhiyun Qian, University of California, Riverside
Code: https://github.com/fiberx/fiber
Topic: Angr
URL: https://www.usenix.org/conference/usenixsecurity18/presentation/zhang-hang
Where: 27th USENIX Security Symposium
Year: 2018
Introducetion: 实现了FIBER工具:针对安卓系统,通过生成签名的方式,判断是否打上了已发布的补丁
本文只是学习并记录笔记,如有错误或不足请谅解指正,谢谢!
一、摘要与背景
主要背景:
软件世界种总是存在着各种漏洞,对抗漏洞的主要方法是打补丁(patch)来修复,对软件进行更新。随着程序开发的发展,代码复用成为了一种常见的开发方式,开源项目能够被很多的开发者重复使用在不同软件程序上。然而,当开源项目出现了(或被发现存在)漏洞,会同时影响到所有复用这个项目的使用者,而当开源项目的维护者打入了补丁、修复了漏洞后,这些复用该项目的程序是否及时地更新了相应的补丁?这会严重影响这些软件的安全性。
因此,能否及时、有效地检测目标程序是否更新了相应的补丁,对于开源软件世界是一个严峻的挑战。
补丁—>对抗漏洞 —>如何确保软件存在安全补丁?
什么是补丁存在度测试:在假设已知受影响的函数和补丁本身的情况下,检查一个特定的补丁是否被应用到一个未知的目标上。
以往的两方面工作:
Source to source:源代码级别:目标是源代码信息,通常需要提供补丁的相应信息
Binary to Binary:二进制特征:单纯地比较二进制文件
二、问题
- 背景:
- 代码开源的情况越来越常见了(Github)
- 许多开源代码或组件在封闭源代码软件中被广泛重用(OpenSSL、Linux-Base Kernel等),因此Source to Source这种源代码级别的检测方法未可用
- 对于Binary-only层面,由于搜索范围非常大,不得不使用基于相似度的模糊匹配(similarity-based fuzzy matching)来加快搜索过程,但精度不够准确;且安全补丁大多是微小的变化,基于相似性的方法无法有效判断是否打过补丁。
- 解决: 为了解决这个问题,作者提出了Fiber这一工具:首先仔细分析开源安全补丁,生成细粒度的二进制签名(fine-grained binary signatures)反映补丁引入的最具代表性的语法和语义变化,用于搜索目标二进制文件。
技术问题:如何生成能很好地表示源代码级补丁的二进制签名?(generate binary signatures that well represent the source-level patch)
步骤:
- 挑选并选择补丁中最合适的部分作为生成二进制签名的候选者
- 生成尽可能保留源代码级信息的二进制签名,包括补丁和相应的函数作为一个整体
贡献:
- 在“源到二进制(Source to Binary)”下制定了补丁存在测试问题,弥合了从一般错误搜索到精确和准确的补丁存在测试的差距
- 在patch中选取最合适的部分,生成代表源代码级patch的二进制签名
- 系统地评估了基于不同时间戳、版本和厂商的Android内核镜像2上的107个真实世界的漏洞和安全补丁,表明FIBER在安全补丁存在度测试中具有较高的准确性
三、相关工作
漏洞搜索如何应用与补丁存在测试问题上
- Source-level bug search
- 一般的目标:寻找与给定的bug代码相似的代码片段
- 漏洞搜索方案通常使用从源代码中提取的特征(包括纯字符串、标记 和解析树 )构建为某种形式的相似性匹配,但这种方法使得确定识别出的类似代码片段是否被修补变得困难(因为打过补丁和未打过补丁的版本可能类似(特别是对于通常很小的安全补丁))
- Binary-level bug search
- 与源码级漏洞搜索类似,为了克服缺乏源级信息(如变量类型和名称)的挑战,需要寻找替代特征,如二进制程序的结构
- 不假设符号表的可用性,因此被迫检查每个函数,即使它只打算对特定函数进行准确的补丁存在性测试
- 现有的解决方案的设计是主要为了速度而不是精度
FIBER处于一个独特的位置,利用源代码级别的信息来回答一个更具体的问题——是否在目标二进制文件中修补了特定的受影响的函数。
系统设计
系统架构
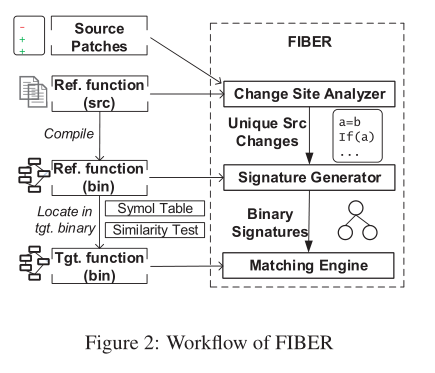
主要输入:
- Source Patches 源代码级补丁信息
- Ref .function(src) 完整的源代码参考
- Ref .function(bin) 编译后的引用二进制中受影响的函数
- Tgt. function(bin) 目标二进制中受影响的函数
三个组件:
- Change site analyzer:分析补丁中每个代码变更点和相应的参考函数来挑选那些最具代表性、独特且易于匹配的源变更,模仿真正的分析师会做的事情
- Signature generator:签名生成器,负责将源级更改点转换为二进制级签名(利用二进制符号执行)
- Matching engine:任务是在目标二进制文件中搜索给定的签名。首先需要在符号表的帮助下在目标二进制文件中找到受影响的函数。然后通过匹配与补丁相关的本地化CFG的拓扑结构所表示的语法来完成搜索,然后是语义公式(由于符号执行而变慢)。
范围:
1、FIBER支持分析不同架构的二进制文件,并使用不同的编译器选项进行编译。
2、FIBER本质上不绑定任何源语言,尽管目前它可以在C代码上工作。需要编译器生成调试信息。
1、Signature
通常,“理想”的签名两个标准:
1、Unique:独一无二,该签名不能在补丁以外的地方找到(这要求签名不能过于简单)
2、Stable:稳定,签名应该对代码库的演化具有适应性(这也要求签名不能过于复杂)
签名是一组二进制指令,它们不仅在结构上与源码级签名相对应,而且还用足够的信息进行注释,以便它们可以明确地映射到原来的源码级更改点。
2、Change Site Analyzer
输入:Source Patches 源码补丁及Ref .function(src) 参考代码库
目的:
- 由于一个补丁可能会在不同的功能内引入多个变化点,分析器的目标是根据“Signature”中提到的标准选择一个合适的签名
- 了解补丁变更的地点
2-1 发现独特的源代码变更(Unique Source Change Discovery)
打补丁的方式有多种,删除、添加、修改,作者主要关注后两种情况。
对于补丁中添加的每行代码,执行以下步骤:
1、独特性测试(Uniqueness test),不仅捕获基于令牌(token-based)的信息,而且捕获与语义相关的信息
2、上下文相关(可选)(Context addition),可以有多个上下文语句
3、细粒度的变化检测(Fine-grained change detection):一般,补丁以源码行变化的形式存在,通过与相邻的已删除或已添加的行比较,可以在单个语句/行中检测这细粒度的变化。确保我们不包括会扩大签名的不必要部分。
4、类型的洞察力(Type insight):源码语句中涉及的变量类型也很重要,因为它将指导后面的二进制签名生成和匹配
2-2选择源代码变更点(Source Change Selection)
上一步可能会为单个补丁生成多个候选的独特代码变更。一个补丁会有多处代码变化,且在实践中,这些变化中的一个的存在可能已经表明补丁的存在。
因此,一些源代码更改比其他的更适合生成二进制签名。
FIBER对上一步产生的代码候选变更点进行排序,并对前N个进行进一步处理(基于三个因素)
1、到功能入口的距离:越近越好
2、函数大小:越小越好
3、代码变化类型(最重要)
将补丁中的代码变化分为几种通用类型:
- 函数调用:新的函数调用或参数的改变,优先级最高(可以根据是否有对该函数的调用判断是否打了补丁)
- 条件相关(if等):同时引入了结构变化和语义变化
- 赋值
等
3、Signature Generator
将参考源代码编译成参考二进制文件,根据所选的独特源代码的变化,将从中生成二进制签名
(保留编译器生成的所有调试信息,以备将来使用)
3-1二进制签名生成(Binary Signature Generation)
识别并组织与源码变更相关的指令
给定参考二进制文件,首先要定位与源代码更改相关的相应二进制指令。(通过调试信息)
本地CFG的拓扑结构反映了原始源码变化的结构
理论上,上述本地CFG中识别的所有指令都将成为二进制签名的一部分。然而,这在实践中并不好,因为只有一个指令子集实际上总结了关键行为(数据流语义);我们把这样的指令称为“根指令”。
(注意:编译器仍然可能为相同的语句生成稍微不同的根指令(由于编译器优化等)。)

只要根指令的类型相同,我们就认为它们是等价的(根指令的规范化)。
需要确保根指令有足够的标签(这是我们的二进制签名),以便它们可以唯一地映射到源代码更改。
从函数的角度,指令中任何操作数只能从四个来源派生:
(1)函数参数(外部输入)
(2)局部变量(在函数中定义)
(3)函数调用返回值
(4)立即数(常量)
并对这四种类型进行不同的处理
根据作者经验,发现即使对签名中的这些基本元素没有精确的了解,描述它们的语义公式通常已经足够独特,可以注释操作数;最终允许我们唯一地将根指令映射到源级语句。
二进制签名匹配:
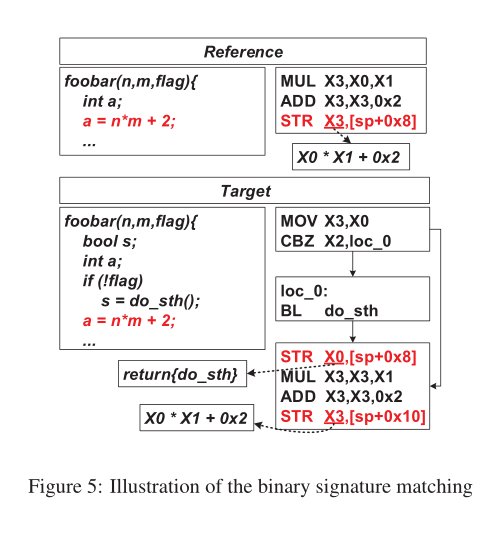
目标源有相同的补丁语句(应该被认为是补丁),即使它也插入了一些带有新的本地变量的额外代码。
尝试匹配二进制签名时,有三点值得注意:
1、不能在引用和目标之间盲目地使用固定偏移量来表示同一个局部变量。策略:(1)推断目标二进制文件中局部变量的类型,并得出结论:sp+0x10是唯一的整数变量,因此必须对应于sp+0x8。(2)分析目标二进制文件中所有局部变量的行为,并尝试匹配引用中最类似sp+0x8的那个。
2、孤立的基本块级分析是不够的
3、在目标二进制文件的最后一个基本块中有一个额外的存储指令,它将X0 (do sth()的返回值保存到sp+0x8(即s)。注意,从数据流的角度来看,这可能看起来像根指令。但是,由于它试图在原始签名中存储返回值而不是公式,因此不会导致错误匹配。
3-2二进制签名验证(Binary Signature Validation)
原因:转化过程中的信息丢失
(1)独特性:对于每个补丁,准备补丁及未打补丁的二进制文件作为对象,再匹配它们的二进制签名,若打了补丁的签名在未打补丁的签名中无法匹配,则说明其独特性。还可能存在一个独特的二进制签名可能有多个匹配的情况。
(2)稳定:源码变化的大小和二进制签名是相关的。还可以准备多个补丁和未补丁的函数二进制版本,并针对它们测试生成的二进制签名。这有助于挑选出那些最稳定的二进制签名,这些签名存在于所有打过补丁的二进制文件中,而不存在于未打过补丁的二进制文件中。
4、签名匹配引擎(Signature Matching Engine)
负责在目标二进制(即测试对象)中搜索给定的二进制签名。
首先需要通过目标二进制中的符号表来定位目标函数,然后开始搜索其中的二进制签名。
粗略匹配
通过一些易于收集的特性来匹配二进制签名,包括:
(1)CFG拓扑。二进制签名本身基本上就是CFG函数的一个子图。
(2)基本块的退出类型(exit)。一般来说,每个基本块都有两种退出类型:无条件跳转(call、return等)和条件跳转。因此可以通过退出类型快速比较基本块。
(3)根指令类型。分析签名中的每个基本块,并确定其根指令集。指令类型可以用来快速比较两个基本块。需要为目标函数二进制中的每个基本块生成数据流图。
通过以上特性,我们可以快速缩小目标函数中的搜索空间。如果在这一步中没有找到匹配,我们已经可以断定签名不存在,否则,我们仍然需要进一步精确地比较每个候选匹配。
精确匹配
利用语义公式对两组根指令执行精确匹配。
首先需要为所有匹配的候选根指令生成语义公式,若语义公式匹配(它们映射到相同的源码级签名/语句),则视为等价
如何比较两个语义公式?(之前有计算相似分数)
但FIBER—明确的答案:定理证明器被用于证明两个公式[14]的语义等价性,这无疑提供了最好的准确性,但不幸的是,在实践中可能非常昂贵。选择了一个中间立场。根据观察,语义公式捕获了依赖关系,因此指令的顺序不能交换,我们知道公式的结构不太可能改变。
基本上,匹配过程只是递归地匹配AST中的运算和操作数,并进行一些必要的松弛(例如,如果运算符是可交换的,则操作数的顺序无关紧要)。
例如:(a+b)2不会变成a2+b*2
实现
使用Angr符号执行引擎生成语义公式。(改变了Angr的内部结构)
架构依赖:
原则上FIBER支持任何体系结构,因为我们可以将源代码编译成任何体系结构的二进制文件。
Angr将二进制文件提升到一种中间语言VEX(它抽象出指令集架构的差异)
根指令注释(Root instruction annotation):
为了生成根指令操作数的语义公式,需要分析从函数入口到根指令的所有二进制代码。我们选择符号执行作为我们的分析方法,因为它可以覆盖所有可能的执行路径,并获得沿着路径上任意一点的任何寄存器和内存位置的值表达式。
作者采用的符号执行路径爆炸优化方法:
(1)路径修剪(Path pruning)。在开始符号执行之前,我们将首先在函数CFG中执行深度优先搜索(DFS),找到从函数入口到根指令的所有路径。然后,我们将只把这些路径中包含的基本块放在执行白名单中,所有其他的基本块将被符号执行引擎删除。此外,我们还将循环展开次数限制为2次,以进一步减少路径的数量。
(2)非约束符号执行(under-constrained symbolic execution):不受约束的符号执行可以处理单个函数,而不用担心其调用上下文,从而有效地将路径空间限制在单个函数中。虽然函数的输入(如参数)在一开始是不受约束的,但它不会影响语义公式的提取,因为它们不需要这样的初始约束。
无约束的输入也可能导致执行引擎在现实世界的执行中包含不可行的路径,然而,我们的语义公式的目标是使它们在引用和目标二进制之间具有可比性,只要我们对双方使用相同的过程,提取的公式仍然可以用于补丁存在测试(patch presence test)的比较。最后,我们使用函数内的符号执行,也就是说,不跟随被调用者(它们的返回值也将不受约。束),这在实践中已经可以生成公式,使根指令唯一且稳定。
(3)验证模式下的符号执行(Symbolic execution in veritesting mode):
验证(veritesting )是一种将静态符号执行集成到动态符号执行的技术,可以提高执行效率。
动态符号执行—基于路径—开销大
静态符号执行—基于基本块—公式更复杂(需要携带所有可以到达当前节点的路径的不同约束)
但FIBER不需要求解这些公式,只需比较这些从参考和目标二进制文件中提取的公式,
当我们认为一个二进制签名在目标中匹配时,我们要求目标中的计算公式包含签名中的所有公式(可以是一个超集)。
评估
评估数据集:Android内核。原因:安卓受欢迎;很多开发分支由不同供应商(华为三星等)维护。其他Android供应商可能不会及时将安全补丁移植到他们自己的内核。
(1)参考内核源代码和安全补丁
(2)目标Android内核映像和源代码
注:供应商发布的二进制映像(有时每月一次)比源代码包要多得多。我们只对能找到相应源代码的二进制映像进行评估,而源代码只能作为patch presence test的ground truth。
实验过程
准备参考二进制 Reference binary preparation.
首先需要将参考源代码编译成二进制文件,并在此基础上生成二进制签名。(自由地选择编译器、它们的选项和目标体系结构,当然应该最接近目标二进制的编译配置)
首先编译多个参考二进制文件与所有的组合常见的编译器(使用gcc和clang)和优化水平(我们使用水平O1 - O3和Os),然后使用BinDiff来测试每个参考二进制和目标二进制的相似性,最相似的参考二进制文件最终将用于二进制签名的生成。
离线签名生成和验证 Offline signature generation and validation.
对于每个安全补丁,我们最多保留三个二进制签名,通过将它们与已修补和未修补的参考内核图像进行匹配来测试它们的唯一性。
在线匹配 Online matching
给定一个特定的安全补丁,我们将尝试在目标内核中匹配它的所有二进制签名。(所有Android内核映像都是用符号表编译的。因此,我们可以很容易地找到受影响的函数。)
只要一个签名能够与引用补丁内核中的匹配,那么我们就会说该补丁存在于目标内核中。
准确性
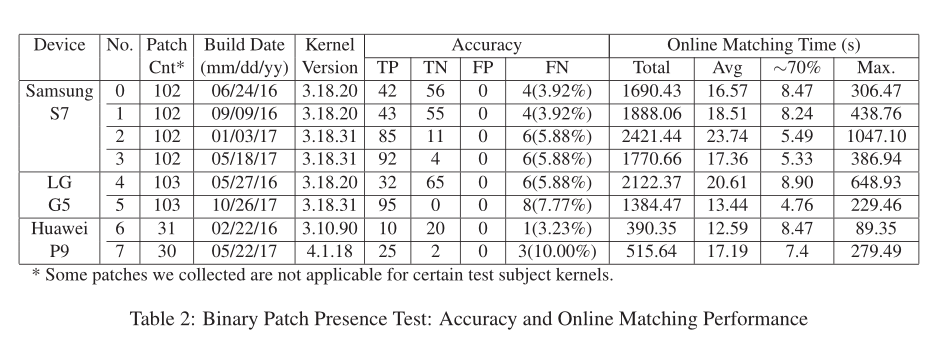
准确性非常好,没有假阳性(FP),非常少的假阴性(FN)。
FP可能会导致开发人员错误地认为已经应用了补丁,而实际上并没有(这是一个严重的安全风险)。
相比之下,FN只会花费一些额外的时间,分析师意识到代码实际上是打了补丁
出现FN的原因:
(1)内联函数:目标内核有不同的内联行为,我们的签名将无法匹配
(2)函数原型变化:有时函数原型会在不同的内核映像之间发生变化(函数参数的数量和顺序可能会有所不同。)
(3)定制代码:由于代码定制,上下文可能会在不同的内核映像之间有所不同
(4)补丁的适应:补丁可能需要针对不同供应商维护的内核进行调整,因为不同内核分支之间的脆弱功能并不总是完全相同。
(5)其他工程问题:例如,某些二进制指令无法被angr识别和解码,这将影响后续CFG的生成和符号执行。
性能
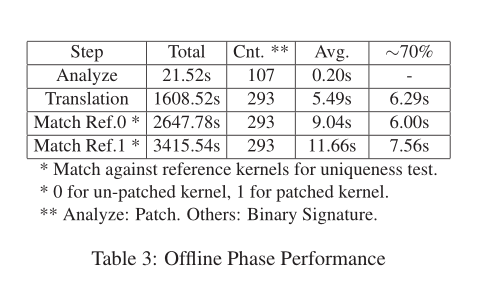
一小部分补丁需要比平均匹配更长的时间,补丁的改变网站定位在非常大的和复杂的功能(例如,cve - 2017 - 0521),因此,匹配引擎可能遇到根深处的指令功能。
未导入的漏洞
FIBER会产生一些TN情况,表面存在未修补的漏洞,如果相关的安全补丁在测试对象的发布日期之前已经可用,那么这意味着测试对象未能及时应用补丁。
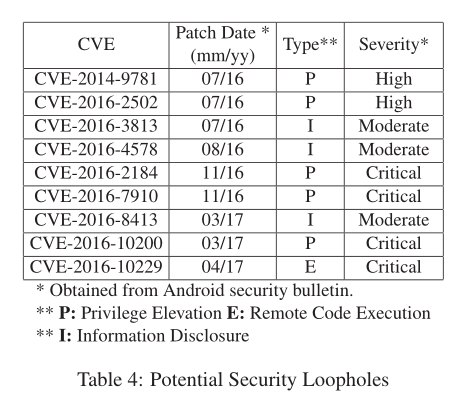
可以看到,即使是一些关键漏洞也没有及时修补,这表明它们很有可能被用来完全破坏内核以执行任意代码。
注意:FIBER旨在测试目标内核中是否存在补丁,但是,缺少安全补丁并不一定意味着目标内核可以被利用。因此,仍需进一步验证。
总结
在本文中,我们提出了“源码到二进制”场景下的补丁存在性测试问题。然后,我们设计并实现了FIBER,这是一个全自动的解决方案,可以充分利用源代码级别的信息,在二进制文件中进行精确的补丁存在测试。FIBER已经通过真实世界的安全补丁和一组不同的Android内核图像进行了系统评估,结果表明,它可以实现良好的准确性和可接受的性能,因此对于安全分析人员来说非常实用。